파이썬 공부(ft. sparta)/1주차
1-2. 스크래핑실습(1)
c_sm
2023. 3. 29. 13:13
뉴스를 스크래핑을 해보자.
requests -> enter을 치는 라이브러리
bs4 -> 잘 솎아내는 라이브러리
colab의 코드에 !pip install bs4 requests 이것을 친 후 실행하면
해당 라이브러리를 다운받게된다.
그리고 웹 스크래핑 기본 코드가 있는데
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query=삼성전자',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
이건 외우는 것이 아니라 다른 이가 만들어놓은 페이지가 있으면 그에 해당하는 코드를 끌어다가 쓰면된다.

그 후 soup을 치고 실행하게 되면 해당 뉴스들 코드들이 쭈우욱 나온다.
그리고 <a 를 오른쪽 클릭 후 copy -> copy selector을 클릭 한뒤 코드에

a = soup.select_one(ctrl+v)
print(a)를 하게 되면 아까 봤던 <a에 해당되는 애들이 나오고,
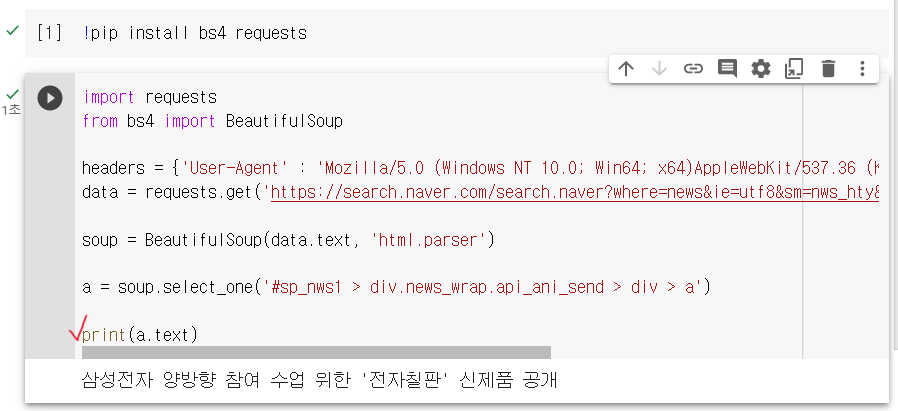
print(a.text)를 하게 되면 제목만 나오게 된다.
그리고

print(a['href']) 를 하게되면 해당 뉴스의 주소를 가져오게 된다.
자 이제 여러 뉴스들을 스크래핑을 할것이다.
우선 해당 뉴스들이 있는 <li></li>들을 다 끌어 모아야 한다.

li들은 ul에 들어와 있으니 copy한 뒤 뒤에 덧붙이면 된다.
저건 ul에서 li들을 넣어줘라 라는 것이다.
그리고

for문을 사용해서 해당 뉴스들을 출력하면 된다.
제목과 주소를 출력해주었다.
그리고 함수화를 하면 어느 것이 됬든 키워드를 입력하면 해당 뉴스를 출력해낼 수 있다.

def get_news(keyword): ->함수를 만들어 준 뒤 나머지를 들여쓰기해서 함수에 해당되게 하고,
저 data = requests.get(f'~~~{keyword}')
제일 앞에 f를 넣어주고 삼성전자라 써져있던곳에 {keyword}를 넣어주면 keyword에 해당되는 뉴스들을 볼수가 있다.